Part 6: AI Meets Robotics · New paradigms
Chapter 17
模仿学习 - “看我做一遍,你来”
上一章我们聊了强化学习:让机器人在仿真环境里疯狂试错,自己摸索出策略。这个思路很美好,但在实践中你经常会卡在一件事上 - 奖励函数怎么设计?
“走到目标点”的奖励还好写,距离缩短就给正奖励。但“把鸡蛋从碗里拿出来放进蛋托”呢?你怎么用一个数值函数来描述“拿起鸡蛋”这个动作的每一步应该得多少分?是捏住的瞬间给奖励,还是抬起来给奖励?捏碎了怎么扣分?倾斜了怎么算?你会发现,为一个看似简单的操作任务设计一个不被机器人“钻空子”的奖励函数,比完成任务本身还难。
模仿学习的思路截然不同:别费劲定义“什么是好的”了,直接示范给它看。就像教一个新厨师切菜 - 你不会给他写一本《切菜行为的数学定义与奖励函数设计》,你会拿起刀切几下说“看到了吧?就这样”。机器人领域管这叫 Learning from Demonstration(LfD),模仿学习是其中最主流的技术路线。
遥操作 - 先得有数据
模仿学习的第一步不是写代码,是采数据。你需要人类操作员控制机器人完成任务,把操作过程中的所有数据(关节角度、末端位姿、图像、力矩等)录下来,作为训练样本。
这就引出了一个关键问题:人怎么操控机器人?
VR 遥操作是目前最火的方案。操作员戴上 Meta Quest 或者 Apple Vision Pro,通过手柄或手部追踪来控制机器人手臂。头显追踪的是操作员手的 6DoF 位姿(三维位置 + 三维旋转),通过逆运动学实时映射到机器人的关节空间。ALOHA 项目(就是 ACT 算法那篇论文用的硬件平台)用的是两台 ViperX 300 机械臂做双臂遥操作,整套硬件成本控制在两万美金以内,在学术界掀起了一阵“低成本模仿学习”的热潮。
VR 遥操作的优点是直觉性强 - 你动手,机器人跟着动,学习曲线很短。缺点是延迟和精度。网络传输加上逆运动学计算,总会有几十毫秒的延迟,对于精细操作(比如穿针引线)这点延迟就够你抓狂了。

主从式遥操作是另一条路。你有一台“主臂”(leader arm),操作员直接用手推拉它,另一台“从臂”(follower arm)实时复制主臂的动作。ALOHA 系统实际上就是这种架构 - 两对主从臂,操作员推动两台 leader 臂,两台 follower 臂同步执行。因为主从臂的运动学结构完全一致,映射关系是直接的关节角对应,延迟极低,精度也比 VR 方案好。
对于人形机器人的全身操控,宇树 G1 的生态里已经有了 Homunculus Exoskeleton 这样的 7 自由度全身控制外骨骼。操作员穿上外骨骼,身体的运动直接映射到机器人全身关节。这种方案的数据质量更高,因为操作员能直接“感受到”机器人的运动范围和物理约束。
不管用哪种方式,关键输出都是一样的:一段一段的 demonstration trajectory(示范轨迹),每一帧包含观测数据(图像、关节角度等)和对应的动作数据(目标关节角度或末端位姿指令)。采集几十到几百条这样的轨迹,你就有了训练数据集。

行为克隆 - 最朴素的模仿
有了数据,最直接的做法叫 Behavior Cloning(行为克隆)。思路简单到令人怀疑 - 把它当成一个监督学习问题:输入是当前观测(图像 + 关节状态),输出是应该执行的动作,训练一个神经网络来拟合这个映射。
# 伪代码,但核心逻辑就是这么简单
for observation, action in demonstration_dataset:
predicted_action = policy_network(observation)
loss = MSE(predicted_action, action)
loss.backward()这和你训一个图像分类器在结构上没有本质区别 - 只不过标签从“猫/狗”变成了“下一步关节应该转到什么角度”。
行为克隆确实能 work。用几十条高质量示范数据训出来的 policy,在简单任务上(比如抓取固定位置的物体)可以达到不错的成功率。但它有一个臭名昭著的问题:compounding error(误差累积),学术界叫它 distribution shift(分布偏移)。
想象你在教一个人沿着悬崖边的小路走。你示范了一遍,他学到了“沿着路的中间走”。但他第一步稍微偏了一点点 - 往悬崖那边偏了 2 厘米。这 2 厘米的偏差导致他看到的景象和你示范时看到的不一样了(你走的时候路在正中间,他走的时候路偏向另一边)。因为他从没在这个“偏移后的视角”下见过训练数据,他不知道怎么修正。于是第二步可能偏了 5 厘米,第三步 10 厘米...几步之后就掉下悬崖了。
这不是理论上的问题,这是每个做行为克隆的人都会遇到的现实。训练时 loss 降到很低,看起来学得很好,一部署到真机上就很快偏离示范轨迹,然后做出完全不合理的动作。DAGGER(Dataset Aggregation)是早期的一个经典应对策略 - 先让机器人按学到的 policy 跑,人类专家在旁边实时标注“如果是我,在你这个偏移后的状态下我会怎么做”,把这些修正数据加回训练集重新训练。但这个方法需要人类专家一直在线,成本很高。
ACT 和 Diffusion Policy - 新一代方案
2023 年以来,两个算法彻底改变了模仿学习的格局:ACT 和 Diffusion Policy。
ACT(Action Chunking with Transformers) 来自 Tony Zhao 等人在 Stanford 的工作。它的核心洞察是:与其一步一步预测动作,不如一次预测一整段动作序列。这叫 action chunking - 每次 policy 输出的不是“下一帧关节该到什么位置”,而是“未来 k 帧(比如 100 帧)的完整动作序列”。
为什么这能缓解误差累积?因为你不再是每一帧都做一次决策了。你在一个关键时刻做一次决策,然后开环执行一整段动作。执行过程中即使有小偏差,下一次决策时 policy 会看到当前的真实状态,重新输出一整段修正后的序列。这比逐帧决策的纠错能力强得多。
ACT 的架构用了一个 CVAE(Conditional Variational Autoencoder)来处理示范中的多模态性 - 同一个任务可能有不同的完成方式,比如先抓左边还是先抓右边。Encoder 部分在训练时看到完整动作序列来推断 style 变量,decoder 部分(一个 Transformer)根据观测和 style 变量生成动作 chunk。
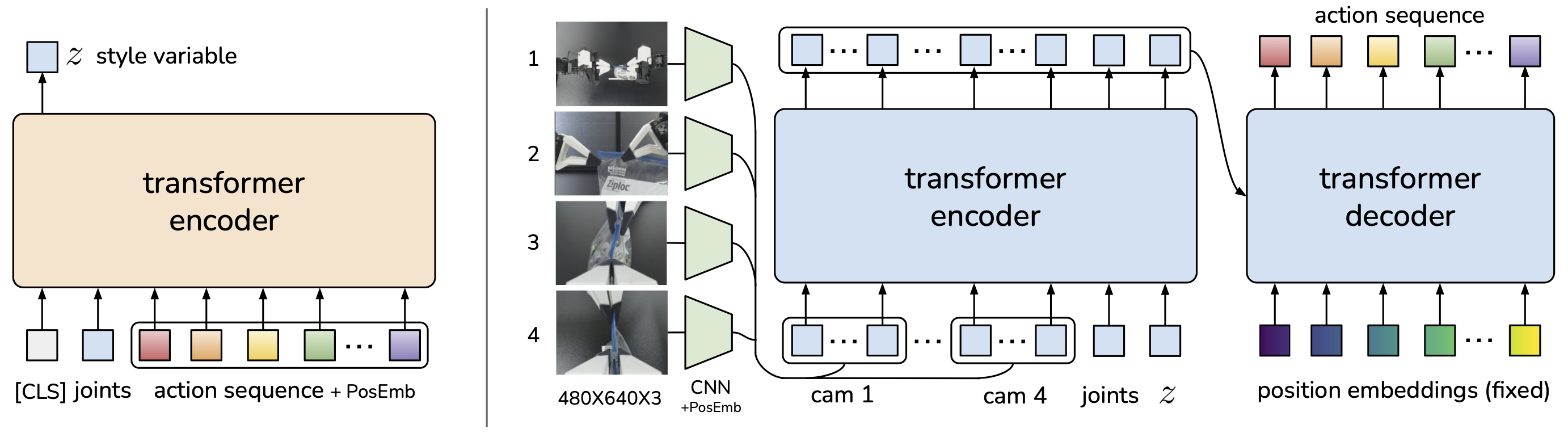
Diffusion Policy 来自 Columbia 大学的 Cheng Chi 等人,思路完全不同但同样优雅。它把动作生成建模为一个去噪扩散过程 - 和图像生成里的 Stable Diffusion 是同一个数学框架。从一团高斯噪声开始,经过多步去噪,逐步“生成”出一段合理的动作序列。
Diffusion Policy 的杀手锏是处理 multimodal action distribution(多模态动作分布)。行为克隆用 MSE loss 训练时,如果同一个状态下有两种合理的动作(左绕和右绕都行),网络会输出两者的平均值 - 一个哪边都不是的错误动作。Diffusion 模型天然能表达多模态分布,它可以随机采样到“左绕”或“右绕”中的任何一种,而不会输出不伦不类的平均。
在实验中,Diffusion Policy 在 12 个 benchmark 任务上比此前最好的方法平均提升了 46.9%。这不是一个渐进式的改进,而是一个代际跳跃。

两个方法各有场景。ACT 架构更简单、推理更快,适合需要高频控制的任务(比如双臂协作操作)。Diffusion Policy 精度更高,但去噪过程需要多步迭代,推理速度慢一些,在需要极高成功率但对实时性要求稍低的场景更合适。实际上很多后续工作已经在融合两者 - 用 action chunking 的思路加上 diffusion 的生成方式。
LeRobot - 开源模仿学习框架
说了这么多算法,实际上手用什么?Hugging Face 的 LeRobot 是目前最活跃的开源模仿学习框架。它做的事情类似于 Hugging Face Transformers 库在 NLP 领域做的 - 把各种模仿学习算法(ACT、Diffusion Policy、TDMPC、VQ-BeT 等)统一到一个框架里,提供标准化的数据格式、训练流水线和评估工具。
LeRobot 的野心不小。它不只是一个算法仓库,而是想覆盖模仿学习的完整工作流:数据采集(支持多种遥操作硬件)、数据管理(兼容 Hugging Face Hub 的数据集格式,可以上传和共享)、训练(内置多种算法实现)、评估(仿真环境对比)、部署(导出 policy 到真机)。
2026 年 3 月发布的 v0.5.0 版本是一个里程碑 - 新增了 Unitree G1 人形机器人的完整支持,训练速度提升了 10 倍,还加入了 PEFT/LoRA 微调支持,让你可以在大型预训练 policy 上做轻量级适配。这个版本合并了 200 多个 PR,社区贡献者超过 50 人,LeRobot 的论文也被 ICLR 2026 接收。
宇树官方也发布了 unitree_IL_lerobot(GitHub 上叫 unitree_lerobot),这是在 LeRobot 框架上针对宇树 G1 双臂灵巧手做的适配。它提供了数据采集、训练、部署的端到端流程 - 如果你手上有一台 G1,这基本是目前最直接的模仿学习上手路径。
一个典型的 LeRobot 工作流大概是这样的:
- 用遥操作硬件采集几十到几百条示范轨迹,数据自动存成 LeRobot 的标准格式
- 选一个算法(比如 ACT),配置好超参数,启动训练
- 在仿真环境(MuJoCo)里评估 policy 的成功率
- 成功率达标后导出 policy,部署到真机
- 在真机上微调 - 可能需要再采集一些真机数据来弥补 sim-to-real gap
踩坑指南
数据质量比数据数量重要十倍。 这是模仿学习最反直觉的一课。你可能觉得“多采点数据总没错吧”,但如果操作员水平参差不齐,或者采集过程中有大量犹豫、停顿、失误,这些“坏数据”会严重污染 policy。一条流畅精确的示范轨迹,抵得上十条磕磕绊绊的。实际操作中,我们经常看到团队花几天时间采了 500 条数据,最后发现精选出 50 条高质量的来训练,效果反而更好。
遥操作延迟会毁掉数据质量。 如果你的遥操作系统有明显延迟(超过 50ms 就能感知到),操作员会不自觉地过度补偿 - 动作变得不自然、轨迹变得锯齿状。这些“被延迟扭曲的数据”训出来的 policy 自然也不会好。调遥操作系统的延迟是采集数据之前必须做好的事。
Action chunk 长度是个敏感参数。 用 ACT 训练时,chunk size k 的选择对结果影响很大。太短(比如 k=10),退化成逐帧预测,误差累积依然严重。太长(比如 k=200),action chunk 内部没有修正机会,遇到扰动就废了。通常从 k=50 到 k=100 开始试,根据任务的时间跨度和需要的精度来调。
多模态问题是隐形杀手。 你在采集数据时可能没意识到,但同一个初始状态下不同操作员(甚至同一个操作员不同次)可能走了完全不同的路径。如果你用朴素的行为克隆(MSE loss),policy 会学到一个两种路径的“平均” - 一个两头不靠的灾难性动作。这时候要么切换到 Diffusion Policy 这类天然支持多模态的算法,要么在数据层面做清洗,确保同一个起始状态下的示范轨迹风格一致。
模仿学习的输出和边界
模仿学习训出来的是一个 visuomotor policy - 一个从观测(通常是图像加机器人本体状态)到动作(关节角度或末端位姿指令)的端到端映射。这个 policy 直接喂给机器人的低层控制器执行,不需要经过传统的感知、规划、控制分离式 pipeline。
这也是它的局限。模仿学习的 policy 本质上只会做你示范过的事。它没有“理解”任务的语义 - 它不知道为什么要先拿起鸡蛋再放进蛋托,它只是学到了“看到这个画面就输出这串关节角度”的模式匹配。泛化能力有限:换一个颜色的鸡蛋可能还行,换一个形状完全不同的物体就可能失败。
下一章要讲的 VLA(Vision-Language-Action)模型正是试图突破这个天花板 - 通过大规模预训练让 policy 具备语义理解和跨任务泛化的能力。模仿学习更像是“技能习得”,VLA 则是试图实现“技能理解”。两者不是替代关系,更可能是互补的 - VLA 负责高层决策和泛化,模仿学习负责精细操作的最后一公里。