Part 6: AI Meets Robotics · New paradigms
Chapter 18
Foundation Models Meet Robotics — VLAs and Embodied Intelligence
You've probably had that moment: the first time you used ChatGPT to write code, the first time Midjourney generated an image, the first time GPT-4 understood a joke in a photo. Each time, it felt like the world shifted.
Now imagine telling a robot "load the dirty dishes from the table into the dishwasher," and it glances at the table, figures out which ones are dirty, locates the dishwasher, works out how to open the door, and places them inside one by one. Not because you pre-programmed every step, but because it "understood" the instruction, "saw" the scene, and "decided" on the actions.
That's what Foundation Models entering robotics are trying to achieve. If the previous chapters on SLAM, Nav2, and MoveIt are the robot's "cerebellum" — handling the mechanics of walking and grasping — this chapter is about giving the robot a "cerebral cortex": a general intelligence layer that understands language, perceives the world, and makes decisions. Sounds amazing. But hold the excitement — we need to have an honest conversation about how far it's actually come.
From LLM to VLA: An Evolution of "Growing a Body"
To understand VLAs, look at three acronyms in a progression:
LLM (Large Language Model) — text only. You feed it text, it outputs text. GPT-4, Claude, Qwen — all LLMs. They can reason, plan, and write code, but they know nothing about the physical world. They have no idea how heavy a cup is or where the edge of the table is.
VLM (Vision-Language Model) — images + text. Show it a photo and ask "what's on the table?" and it answers "a red cup and a book." GPT-4o, Qwen-VL — these are VLMs. They can "see," but they can't "act." Their output is still text.
VLA (Vision-Language-Action) — images + text + action output. Feed it the robot's camera stream and an instruction like "put the red cup on the left," and it directly outputs how the robot's joints should move. This is the real closed loop from perception to action.
The underlying idea is the same across all three: use the Transformer architecture to unify different modalities. LLMs turn text into token sequences. VLMs add image tokens. VLAs encode robot actions as tokens too — joint angles and end-effector positions get discretized into a sequence of "action tokens" and trained alongside text and image tokens in the same model.
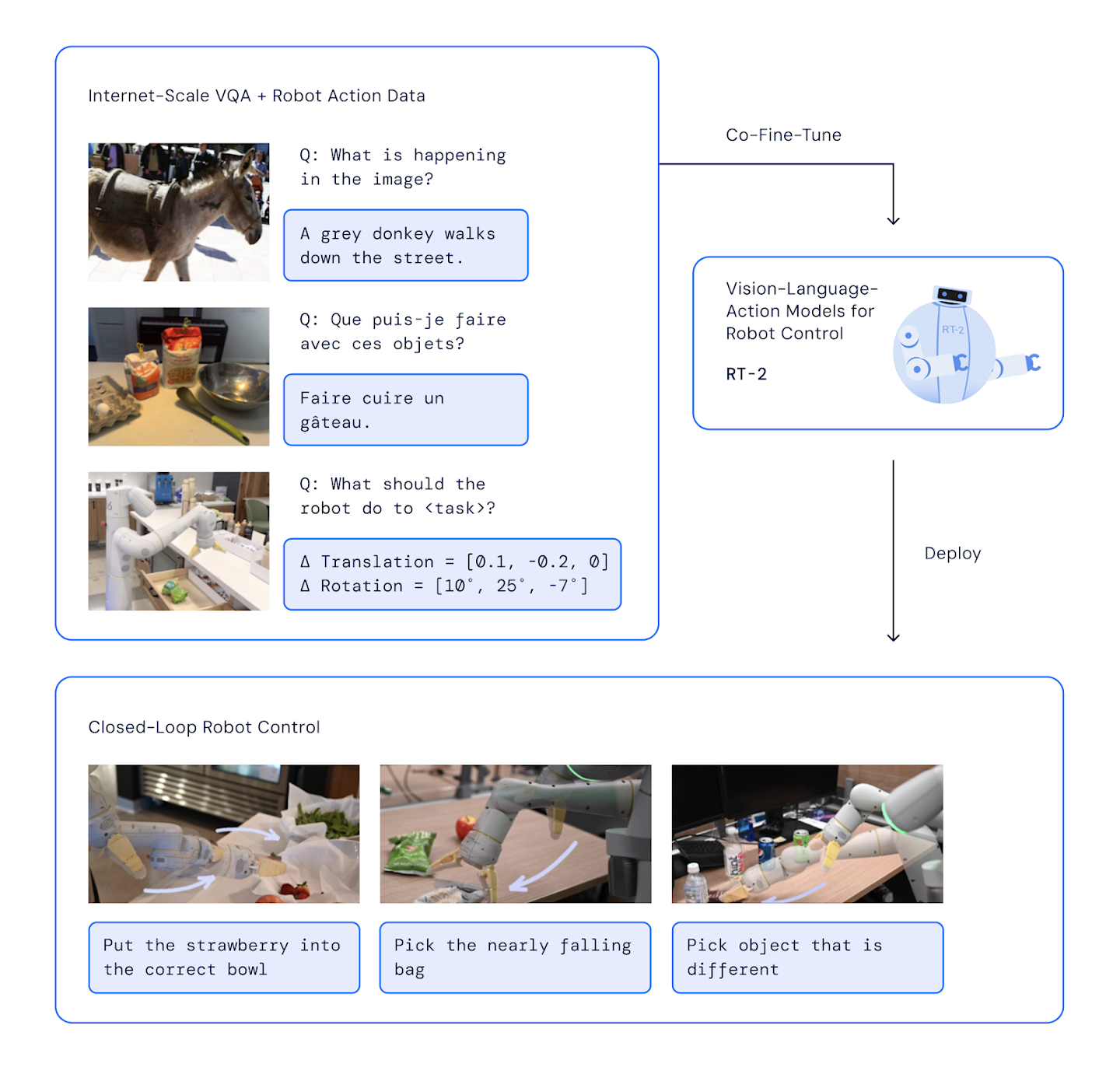
This idea was first validated by Google DeepMind's RT-2 in 2023. RT-2 fine-tuned a large-scale VLM (PaLI-X) to represent robot actions as text tokens (like "1 128 91 241 5 101 127"), having the model "speak" actions the same way it speaks language. The results were striking: the model could not only execute tasks seen during training but showed genuine generalization — for instance, correctly handling a never-before-seen object when given the instruction "move the smallest object aside."
Who's Playing in This Space?
The number of players and models in this field has exploded over the last two years. Here are the most representative:
Google DeepMind RT Series. RT-2 was the trailblazer that proved the VLA approach was viable. The follow-up RT-H (Robot Transformer with Hierarchies) introduced action hierarchy — instead of jumping straight from language instructions to joint angles, it first predicts intermediate "language actions" (like "move the arm forward," "rotate right"), then maps those to low-level motor commands. This hierarchical structure significantly outperforms flat approaches in multi-task settings, with a 15% success rate improvement over RT-2.
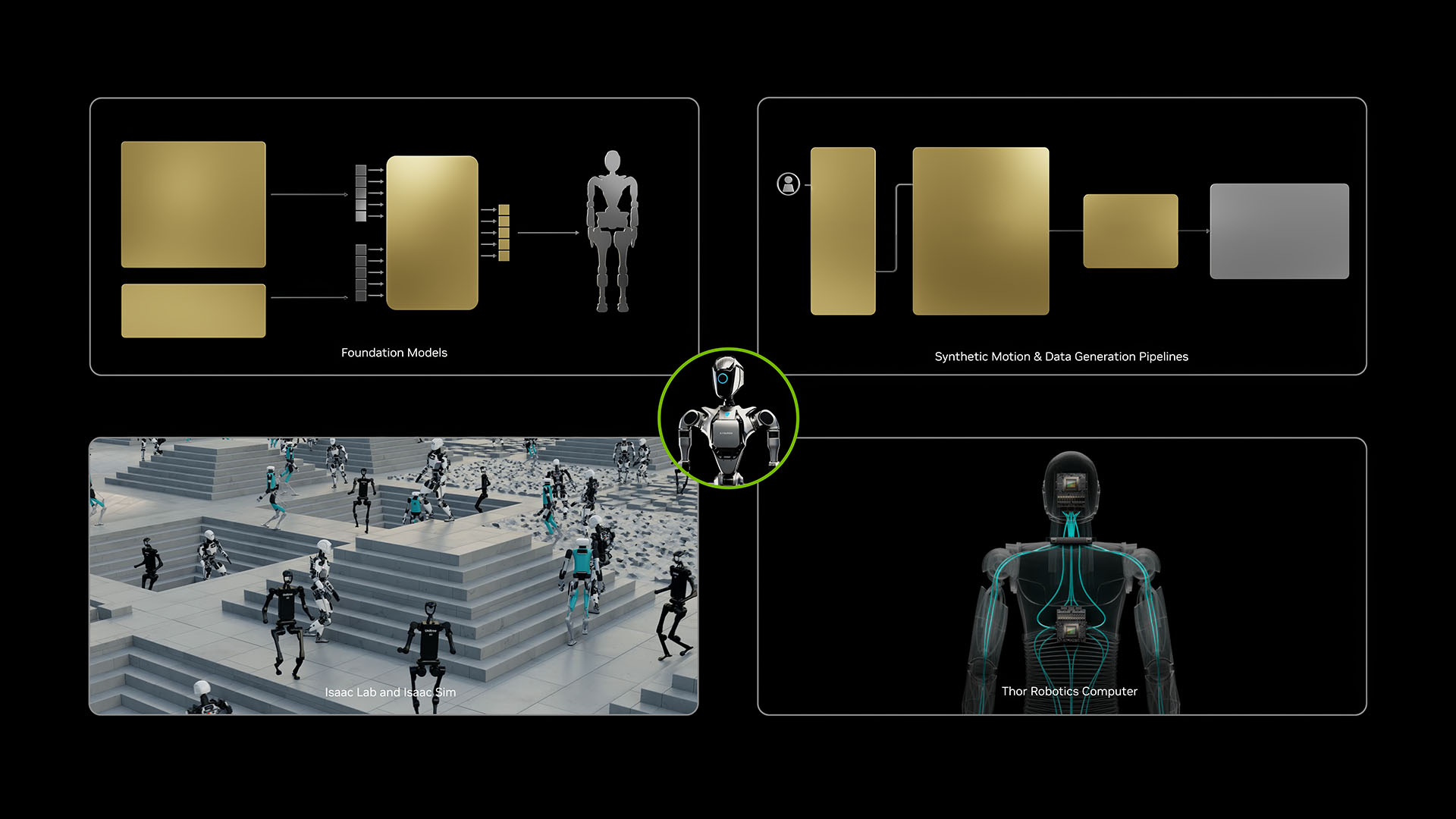
NVIDIA GR00T N1 Series. NVIDIA released GR00T N1 in March 2025, positioned as "the first open foundation model for humanoid robots." It uses a dual-system architecture: a fast action model handles real-time control and action generation (running on-device), while a slow VLM handles scene understanding and task planning. By version N1.5, success rates on the DreamGen simulation benchmark jumped from 13.1% to 38.3%. The latest N1.6 (announced at CES 2026) further refined the architecture and data pipeline. NVIDIA's strategy is clear: be the "Android" of robot AI — open-source the models, but you need their Isaac simulation platform to train and deploy.

Galbot GraspVLA / GroceryVLA. This is a fascinating case. GraspVLA is the first VLA foundation model specifically targeting grasping, trained on SynGrasp-1B — a billion-frame synthetic dataset. It achieves zero-shot grasping: give it an object it has never seen, and it grasps it successfully without any additional training. Building on this, GroceryVLA specializes for retail — at WAIC 2025, it demonstrated autonomous shelf-stocking across hundreds of different products. This suggests that VLAs' path to real-world deployment may not be "universal generalist" but rather "go deep in a vertical first."

Physical Intelligence (Pi) — The pi-0 Series. Co-founded by Karol Hausman (Google Brain), Sergey Levine (UC Berkeley), and Chelsea Finn (Stanford). pi-0 is a 3-billion-parameter VLA that uses flow matching to generate continuous action trajectories at 50Hz, trained across 7 robot embodiments and 68 tasks. pi-0.5 added a hierarchical architecture (predict textual subtasks first, then low-level actions). pi-0.6 brought RL into VLA fine-tuning, doubling throughput on real-world tasks. Code and weights are fully open-source (the openpi repo), making it the most widely reproduced and extended VLA baseline in the community.

Skild AI — "One Brain for Every Body." Founded by CMU's Deepak Pathak and Abhinav Gupta. Instead of training models for specific robot form factors, they're building an omni-bodied foundation model — the Skild Brain. Same model controls quadrupeds, humanoids, tabletop arms, and mobile manipulators without robot-specific adaptation. Valued at $14 billion — the highest among pure-play robotics foundation model companies. That said, how much of the "one model for all robots" vision will actually materialize remains an open question with plenty of skeptics.
General Intuition — Learning Spatial Reasoning from Gameplay. Spun out of Medal (a platform with 2 billion gameplay clips), the core insight is: first-person gameplay video is rich with spatial-temporal reasoning. Train AI agents to learn physical patterns from game data, then transfer to real-world robots and drones. This is a world model approach — learning physical intuition from game interactions rather than real robot data. OpenAI is reportedly spending heavily on gaming data for similar reasons. The key challenge: whether the game-to-real transfer gap can actually be bridged.
Unitree UnifoLM Series. Unitree released two models across 2025-2026: UnifoLM-WMA-0 is a World Model-Action architecture — its core is a world model that doubles as both a simulator for generating synthetic training data and a predictor for optimizing decisions through anticipated future interactions. UnifoLM-VLA-0 (released January 2026) scored 98.7 on the LIBERO simulation benchmark — the highest score among all VLA models, surpassing OpenVLA, InternVLA, and Physical Intelligence's pi-0 series. Both models are open-source, a bold move for a hardware manufacturer.
How LLMs Actually Get Used on Robots: Not Direct Joint Control
After reading about all those VLA models, you might think the future is a single end-to-end model handling everything. But in the engineering reality of 2026, the most mature use of LLMs/VLMs on robots isn't VLA-style direct action output — it's high-level task planning and natural language interaction.
Three patterns, ranked by maturity:
Pattern 1: Task Planner. The user says "clean up the table." The LLM decomposes it: "1. Detect all objects on the table → 2. Classify (trash vs. dishes vs. food) → 3. Throw trash in the bin → 4. Put dishes in the sink → 5. Return food to the fridge." Each step calls an existing skill module (perception, navigation, grasping). The LLM itself never touches low-level control. This is by far the most mature and widely used pattern.
Pattern 2: Natural Language Interaction Layer. The robot encounters ambiguity during a task — "put that thing over there." What thing? Where's "there"? The LLM combines visual input to disambiguate, or directly asks the user: "Do you mean the red cup?" This gives the robot a form of commonsense reasoning, freeing users from needing to specify precise coordinates.
Pattern 3: VLA End-to-End Control. What we discussed above — directly outputting actions from vision + language. Getting better fast, but still far from production-ready on reliability and safety (more on that below).
Most teams in practice use Pattern 1 or 2: the LLM serves as the "brain" for understanding and planning, then calls traditional perception, navigation, and manipulation modules for execution. This leverages the LLM's language understanding while keeping safety-critical low-level control out of the hands of a probabilistic model.
MCP (Model Context Protocol) and Robots: A Standard Protocol for Giving LLMs "Hands and Feet"
If the LLM needs to call robot skill APIs, there needs to be a standard interface protocol. That's where MCP comes in.
You may have already encountered MCP in AI tooling — it's an open protocol launched by Anthropic in 2024 that defines how LLMs discover and invoke external tools. In software development, MCP lets Claude read files, query databases, and call APIs. In robotics, those "tools" become robot skills: move_to_position, detect_objects, pick_up, navigate_to.
This trend has accelerated dramatically over the past year. A few notable examples:
Unitree Go2 MCP Server. An open-source project that runs an MCP server on the Unitree Go2 quadruped. Tell the LLM "walk to the couch and sit down," and it translates that into motion commands via MCP calls to the Go2's ROS 2 services. Open-source on GitHub under Apache-2.0.
ROS 2 Bridge MCP Server. A more general approach that exposes ROS 2 services and topics directly as MCP tools and resources. This means any MCP-compatible AI tool (Claude, GPT, etc.) can talk directly to a ROS 2 robot — publishing motion commands, reading sensor data, triggering navigation tasks.
Dimensional OS (DimOS) MCP Integration. DimOS is a Python-first agentic operating system for robots, built on top of ROS 2 but treating LLMs/VLMs as first-class citizens. It ships with a built-in MCP server that wraps the robot's core capabilities — navigation, detection, movement, visual servoing — as standard MCP tools. This means you can "vibecode" a robot in natural language from your terminal — type "explore this room" and DimOS coordinates LLM planning, ROS 2 navigation, and sensor data streams to execute. It supports multiple robot form factors (Unitree Go2 quadruped, AgileX Piper arm, MAVLink drones, and more) and is currently one of the most complete open-source frameworks for connecting foundation models to ROS 2 robots. It's essentially a standardized abstraction layer between LLMs and robot hardware — if ROS 2 is the robot's "operating system," DimOS is aiming to be the "AI-native operating system."
The significance of MCP in robotics goes far beyond "convenient API calls." The deeper value is composability — you can expose skills from different sources (Nav2's navigation, MoveIt's manipulation, your custom perception pipeline) uniformly to the LLM, letting it freely compose them based on what the task requires. This is far more flexible than hardcoding a behavior tree, though it can't yet fully replace behavior trees in terms of reliability.
Reality Check: Cool Demos, But How Far from Reliable Deployment?
By this point you're probably getting excited. But as someone who has shipped production code, you're going to ask: can any of this actually be used?
The honest answer: demos are genuinely impressive, but there's a very real gap to production-ready.
A few core issues:
Reliability isn't there. NVIDIA GR00T N1.5's success rate on a simulation benchmark is 38.3%. Even if N1.6 improves dramatically, imagine your product manager's face when you tell them "our robot has a 60% chance of completing this task." Industrial scenarios demand 99%+ reliability — one failure can mean a damaged product, an injured person, or an entire production line grinding to a halt. VLAs perform decently in controlled lab environments, but real-world long-tail cases — sudden lighting changes, never-before-seen object shapes, sensor noise — remain their Achilles' heel.
Inference latency. VLA models typically need hundreds of milliseconds to several seconds per inference. That's fine for "place this cup on the table" — a non-urgent task. But for situations requiring real-time reactions (someone steps in front of a walking robot, an object slips during grasping), this latency is unacceptable. This is exactly why GR00T N1 uses a dual-system design — a fast system for real-time control, a slow system for planning.
Blurry safety boundaries. Traditional robot systems have explicit safety constraints: joint torque limits, velocity limits, collision-detection emergency stops. These are deterministic rules. When you hand control to a probabilistic model, how do you guarantee it won't output an action that swings the arm into someone's face? The current approach is usually wrapping a safety filter around the VLA, but defining "safe" is itself an open problem.
Data hunger. Training a good VLA model requires enormous amounts of robot manipulation data. But collecting robot data costs orders of magnitude more than scraping internet text and images — you need real hardware, real environments, real manipulations. Synthetic data from simulation (like GraspVLA's SynGrasp-1B dataset) is the main workaround, but the sim-to-real gap persists.
A cautionary tale: One team built a VLA-powered tabletop tidying demo — 85% success rate in the lab. Swapped the table color: dropped to 40%. Changed the camera angle: dropped to 20%. Turns out the model had massively overfit to the visual background and camera pose from training. They ended up reverting to a traditional perception + planning + control pipeline, using the LLM only at the top level for task planning. This is the honest reality of most deployment projects today.
So for AI developers, the most pragmatic strategy is: use LLMs/VLMs for high-level understanding and planning (Patterns 1 and 2), use traditional modules for low-level execution, and keep a close eye on VLA progress. This field evolves nonlinearly — something you thought was "ten years away" last year might have a paper this year that doubles the success rate. But before deploying it to a real product, always ask yourself: what's the worst-case failure? How much uncertainty can you afford?
Foundation models entering robotics is an irreversible trend, but the way they'll reshape "robot development" probably isn't by replacing SLAM, Nav2, and MoveIt, but by adding a layer of understanding and reasoning on top of them. The most valuable skill set over the next few years may belong to people who understand both worlds — the capability boundaries of foundation models and the safety constraints of robot systems engineering.